
It’s been too long since I’ve been able to return to the longstanding B-plot of my blog: The science of our cephalopodic peers. Really outstanding squid science doesn’t come along very often, in part because the enigmatic beasts — particularly the deep-living ones — are so hard to study. They roam mostly in solitude, generally eschewing contact with one another: The flesh UFOs of the briny deep. But every one in a while we get some really good video evidence of their activity. And what do we find?
Frenetic orgies of gay squid sex.
That’s the conclusion of “A shot in the dark: same-sex sexual behavior in a deep-sea squid”, the title of which ought to win some sort of literary award. The researchers got their hands on footage of 108 Octopoteuthis deletron, a squid that lives at mesopelagic depths (i.e. 200 meters to 1,000 meters). What the scientists were looking for was evidence of how, precisely, these squid mate with each other.
Here’s the thing: Given how deep O. deletron live, they don’t have much light to work with. Scientists have always suspected that the male squid have no idea whether the partners they randomly encounter during their plutonian wanderings are, y’know, female. So what does O. deletron do? Sniff out some subtle odor? Detect some faint bioluminescent marker of the sex of its potential partner?
Nope. It’s much simpler.
They just try to have sex with anything they come in contact with.
When the scientists took screengrabs of the squid, they found that the male and female squid were equally like to display evidence of having had sex with another dude. During sex, the male ejaculates packets of sperm towards its partner, which implant themselves in the partner’s skin. (The packets are called “spermatangia”, and there’s an animation of how it works here that is very cool but which you may not want to watch just before you eat or something.) Anyway, the fact that the male squid and female squid were equally shot up with sperm indicates that “male squid routinely and indiscriminately mate with both males and females.”
Why aren’t they more careful? Because the cons of trying to mate with anything that moves (it’s inefficient; you lose a lot of sperm that way) are outweighed by the fact that if you try to carefully verify the sex of the rare squid you encounter, you might never have sex. It’s a volume business. Or as the researchers put it:
The combination of a solitary life, poor sex differentiation, the difficulty of locating a conspecific and the rapidity of the sexual encounter probably results in the observed high frequency of spermatangia-bearing males in this species. Apparently, the costs involved in losing sperm to another male are smaller than the costs of developing sex discrimination and courtship, or of not mating at all. This behaviour further exemplifies the ‘live fast and die young’ life strategy of many cephalopods.
Finer scientific prose cannot be had.
This sort of indiscriminate gay male sex has not been observed in other flavors of squid, by the way. Apparently male Octopoteuthis sicula have been found with spermatangia implanted in their skin, but in that case it appears to have been a sort of autoerotic mistake. If you’re a squid having sex it’s super dark, you can’t see anything, and there are a lot of limbs flailing around … so apparently it’s pretty easy to shoot yourself with your own sperm. (Or as the authors put it: “Accidental self implantation during mating with a female is also a possibility.”)
By the way, that paper is available for free in full text; it’s only four pages long and is really a blast to read, so go check it out!
(That picture is from the Monterey Bay Aquarium Research Institute!)

Dig this: In 1912, the Spanish civil engineer Leonardo Torres y Quevedo created an analog computer that could play a simple endgame of chess against a human, and always win. The computer was given a king and a rook; its human opponent, a king. The machine would sense where the pieces were via magnets in the bases of each chess piece. If the human made an invalid move, the computer would detect it and flash a light. It wasn’t an efficient player — it couldn’t reach checkmate in a minimum number of moves, nor could it always win within the “50 move rule.” But otherwise it crushed the puny human every time. He called it “El Ajedrecista” — the chess player.
Torres first showed the machine off in public at the Paris World Fair in 1914, and a year later Scientific American showed up to take some pictures and publish a fantastic account of the machine. The entire story is available here on Google Books, and it’s fascinating to read — particularly the author’s meditations on the nature of computer “thought”.
The author notes that while engineers had successfully encoded bits of judgement and self-control in machines — such as torpedoes that steer themselves — that type of activity “is not a complicated one, and the result is easily obtained.” As he continues …
But when it comes to an apparatus in which the number of combinations makes a very complex system, analogous in a small degree to what goes on in the human brain, it is not generally admitted that a practical device is possible. On the contrary, M. Torres claims that he can make an automatic machine which will “decide” from among a great number of possible movements to be made, and he conceives such devices, which properly carried out, would produce some astonishing results. Interesting even in theory, the subject becomes great practical utility, especially in the present progressive industries, it being characterized, in fact, by the continual substitution of machine for man; and he wishes to prove that there is scarcely any limit to which automatic apparatus may not be applied, and that at least in theory, most or all of the operations of a large establishment could be done by machine, even those which are supposed to need the intervention of a considerable intellectual capacity. [snip]
The novelty in the matter is that the machine looks over the field and selects one possible action in preference to another. There is, of course, no claim that people think or accomplish things were thought is necessary, but its inventor claims that the limits within which thought is really necessary need to be better defined, and that the automaton can do many things that are popularly classed with thought.”
That’s a pretty solid piece of prognostication! The rise of the machines was evident even in 1915, it seems.
By the way, if you want to know the algorithm that governed Torres’ machine, Scientific American published this nifty chart breaking it down:
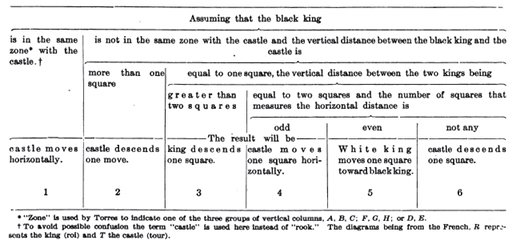
Chess has long been seen as the empyrean of human thought, of course, so the Scientific American author was simultaneously smitten and freaked out. (The story’s headline: “Torres and His Remarkable Automatic Devices: He Would Substitute Machinery for the Human Mind”.) It’s pretty much the same reaction that mainstream journalists had 80 years later when Gary Kasparov faced down IBM’s Deep Blue. (The Newsweek headine back then: “The Brain’s Last Stand”.) Of course, chess grandmasters had long predicted that any machine using a brute-force approach would— given enough processing speed — beat Kasparov; humans don’t really think the way computers do, not do computers “think” like humans. Which is why the truly interesting thing that came out of Deep Blue’s victory was Kasparov’s next move. He decided it would be more interesting to have humans and computers collaborate together as teams, each bringing their peculiar strengths to the table, and thus “Advanced Chess” was born — a computer and a human versus a computer and a human. I’ve blogged and written in Wired about this in the past because it’s so damn interesting. Indeed, I’d argue that Advanced Chess is far more relevant to the way we interact with machines than the Deep Blue match: The value of machine intelligence is precisely how different it is from human intelligence, not how similar. And of course we live today with the constant delights and traumas of cognitively co-operating with digital machines — everything from spellcheck to twitter to GPS to packet switching.
Oh and hey! Because that issue of Scientific American is out of copyright, you can not only read the entire issue via Google Books, but download it as a PDF! I would thoroughly encourage you to do so. It’s filled with the most awesome reports of deranged experiments: A newfangled “even keel” airplane, a “Built-In Hollow Method for Mounting Small Animals”, and an audacious plan to eliminate fog off San Francisco bay by blasting the bay air with massive voltage. Hot damn.

It’s hard to hack cars these days. Open up the hood: The guts of an automobile have become an inscrutably tightly-packed puzzle of precision-engineered pieces and patented software. The panels are, by design, essentially unrepairable; when damaged, they’re built to be pulled off and replaced wholesale.
Granted, there are still folks hotrodding and hacking cars, and just today Ford announced that it would soon allow geeks to put Bug Labs open-source hardware modules in their cars. But if you want to get a sense of how un-DIY the car has become, check out this New Yorker piece from 1936 — “Farewell, My Lovely” — in which E. B. White, in hilarious and gorgeous prose, memorializes the Model T. It turns out that pretty much everyone was modding the heck out of their cars, pretty much as soon as they drove them off the lot:
There was this about a Model T; the purchaser never regarded his purchase as a complete, finished product. When you bought a Ford, you figured you had a start — a vibrant, spirited framework to which could be screwed an almost limitless assortment of decorative and functional hardware. Driving away from the agency, hugging the new wheel between your knees, you were already full of creative worry. A Ford was born naked as a baby, and a flourishing industry grew up out of correcting its rare deficiencies and combating its fascinating diseases. Those were the great days of lily-painting. I have been looking at some old Sears Roebuck catalogues, and they bring everything back so clear.
First you bought a Ruby Safety Reflector for the rear, so that your posterior would glow in another car’s brilliance. Then you invested thirty-nine cents in some radiator Moto Wings, a popular ornament which gave the Pegasus touch to the machine and did something godlike to the owner. For nine cents you bought a fan-belt guide to keep the belt from slipping off the pulley. You bought a radiator compound to stop leaks. This was as much a part of everybody’s equipment as aspirin tablets are of a medicine cabinet. You bought special oil to stop chattering, a clamp-on dash light, a patching outfit, a tool box which you bolted on the running board, a sun visor, a steering-column brace to keep the column rigid, and a set of emergency containers for gas, oil and water - three thin, disc-like cans which reposed in a case on the running board during long, important journeys - red for gas, gray for water, green for oil. It was only a beginning. After the car was about a year old, steps were taken to check the alarming disintegration. (Model T was full of tumors, but they were benign.) A set of anti-rattlers (ninety-eight cents) was a popular panacea. You hooked them on to the gas and spark rods, to the brake pull rod, and to the steering-rod connections. Hood silencers, of black rubber, were applied to the fluttering hood. Shock absorbers and snubbers gave ‘complete relaxation’. Some people bought rubber pedal pads, to fit over the standard metal pedals. (I didn’t like these, I remember.) Persons of a suspicious or pugnacious turn of mind bought a rear-view mirror; but most Model T owners weren’t worried by what was coming from behind because they would soon enough see it out in front. They rode in a state of cheerful catalepsy.
(This is a seriously delightful piece of writing. Print it up or splort it into Instapaper or something, and save it for later this evening. You’ll be glad you did.)
But back to hacking. Obviously, there are good reasons cars aren’t hackable these days. Society and the marketplace has demanded they be much safer, so they’re much more tightly regulated and meticulously engineered. (Those unreplaceable panels are both a feature and bug: Sure, you can’t bang them back into shape and reattach them … but in the process of being crushed, they absorbed so much energy they probably saved your life.) But I can’t help but think that if cars hadn’t become such sealed black boxes — if their owners still tinkered with them as much as Model T owners did — then we might have seen many more cool experiments in hacking them for ultra-high mileage.
(That picture above from Chad Horwedel’s Creative-Commons-licensed Flickr stream!)
“How did you find my site?”
I get asked this question a lot. Whenever I call up someone to interview them — because I’ve read their scientific paper or their blog posting or looked at their company online — they inevitably ask me a variant of that question. (“How’d you find my paper? My company?” etc.) It’s a natural thing to wonder about.
The problem is, I often can’t answer it.
If I’ve heard about the interviewee via a recommendation from a friend, or via a story I read in, say, the Wall Street Journal, then sure, I can usually remember how I found them. But at least 50% of the time I encountered their work during online surfing …
… and this is where my trouble begins. Because the truth is, while I love finding cool things online, it’s often incredibly hard to reconstruct precisely how I stumbled across them. This is why I’ve always thought the corporate name for StumbleUpon is so brilliant: The process of finding something really does feel like stumbling. You careen about digressively, following intuitions, doing a couple of searches, getting distracted (destructively and productively), when suddenly — wham — you discover you’re reading something that is zomg awesome. You follow a link in page A that mentions post B that ports to tweet C that is from person D who posted on their personal site about E.
But later on, it’s damn hard to recall precisely how A led to E. You could look at your web history, but it’s an imprecise tool. If you happened to have a lot of tabs open and were multitasking — checking a bit of web mail, poking around intermittently on Wikipedia — then the chronological structure of a web “history” doesn’t work. That’s because there’ll be lots of noise: You’ll also have visited sites G, M, R, L, and Y while doing your A to E march, and those will get inserted inside the chronology. (Your history will look like A-G-B-M-R-C-D-L-Y-E.) Worse, often it’s not until days or weeks after I’ve found a site that I’ll wonder precisely how I found it … at which point the forensic trail in a web history is awfully old, if not deleted.
But hey: Why does this matter? Apart from pecuniary interest, why would anyone care about the process by which you found a cool site?
Because there’s a ton of interesting cognitive value in knowing the pathway.
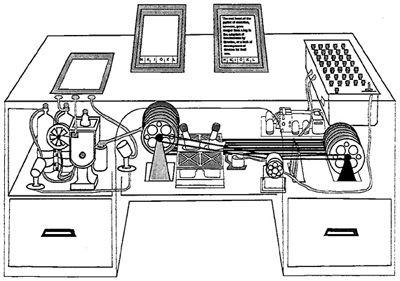
If you’re reading this blog, you are probably least part nerd, which means you’ve likely read (or have heard of) Vannevar Bush’s 1945 essay for the Atlantic Monthly, “As We May Think”. Bush’s essay has become famous amongst digital folks because of how eerily he predicted the emergence of a hyperlinked Internet. “As We May Think” is, at heart, a complaint about information overload (in 1945!) and a suggestion of how to solve it: By building better tools for sorting, saving, and navigating stuff. Bush envisioned a “memex”, a desk-like tool at which you’d sit, reading over zillions of documents stored via microfilm. You could also write your own notes and reflections (which would saved in microfilm format too, photographed automatically via a forehead-mounted webcam “a little larger than a walnut”. That illustration above is a rough mockup of a Memex, by the way.)
The really Nostradamusian element, though, was the hyperlinks. An essential part of the memex, Bush envisioned, would be its system for letting you inscribe connections between documents. He described someone doing research into the history of the “Turkish bow”: The user pores over “dozens of possibly pertinent books and articles”, finds one particularly useful one, then another, and “ties the two together”. He continues on, adding in his own “longhand” notes, and eventually he “builds a trail of his interest through the maze of materials available to him.”
This is, of course, precisely how one does research online today. Except for one big difference: We don’t really have tools for saving what Bush calls the “trail” — the specific pathway by which someone went from one document to another. Sure, we share the results of our online surfing. We do that all the time: Links posted to Twitter, Facebook, a gazillion public fora. But when someone asks “how’d you find that? What was your pathway?”, we often don’t know. We share the results of our knowledge formation, but not how we formed it.
Yet when you read “As We May Think”, Bush clearly thought there was enormous value in sharing the trail. He talks about that specifically in the case of the Turkish bow example, and then describes a few others, too:
And his trails do not fade. Several years later, his talk with a friend turns to the queer ways in which a people resist innovations, even of vital interest. He has an example, in the fact that the outraged Europeans still failed to adopt the Turkish bow. In fact he has a trail on it. A touch brings up the code book. Tapping a few keys projects the head of the trail. A lever runs through it at will, stopping at interesting items, going off on side excursions. It is an interesting trail, pertinent to the discussion. So he sets a reproducer in action, photographs the whole trail out, and passes it to his friend for insertion in his own memex, there to be linked into the more general trail.
Wholly new forms of encyclopedias will appear, ready made with a mesh of associative trails running through them, ready to be dropped into the memex and there amplified. The lawyer has at his touch the associated opinions and decisions of his whole experience, and of the experience of friends and authorities. The patent attorney has on call the millions of issued patents, with familiar trails to every point of his client’s interest. The physician, puzzled by a patient’s reactions, strikes the trail established in studying an earlier similar case, and runs rapidly through analogous case histories, with side references to the classics for the pertinent anatomy and histology. The chemist, struggling with the synthesis of an organic compound, has all the chemical literature before him in his laboratory, with trails following the analogies of compounds, and side trails to their physical and chemical behavior.
The historian, with a vast chronological account of a people, parallels it with a skip trail which stops only on the salient items, and can follow at any time contemporary trails which lead him all over civilization at a particular epoch. There is a new profession of trail blazers, those who find delight in the task of establishing useful trails through the enormous mass of the common record. The inheritance from the master becomes, not only his additions to the world’s record, but for his disciples the entire scaffolding by which they were erected.
The entire scaffolding by which they were erected: I love that phrase. What Bush is talking about here, I’d argue, is metacognition: Thinking about thinking, knowledge about the way we make knowledge. He understood that knowing how someone thinks and searches and finds is as valuable as the the things they’ve actually found.
Our society doesn’t have a lot of tools for sharing thought processes. Scholars and scientists have developed some, in academic papers: They have formal requirements to “show their work” and talk through how they’ve come to a new conclusion. And of course, a well-written nonfiction argument talks you through evidence in a way that’s a bit similar. But in the modern age, though, one could imagine everyday tools would help us peel back the mystery of our online searching, finding, and thinking. I’d love to have a tool that represented my web history in a more semantically or graphically rich way — clustering individual things I was reading by their “trail”, to use Bush’s term. And I’d love to be able to share that with someone else — and see their trails, too.
Indeed, we clearly have an appetite for knowing how and where people found stuff. Every time someone creates a new tool for publishing online — blogs, status updates, social networks, you name it — users on a grassroots level immediately create conventions for elaborately backlinking and @crediting where they got stuff from. It’s partly reputational, but it also betrays the fact that we seriously enjoy associational thinking and finding.
Now, It’s quite likely that such a “trail” tool exists and I simply don’t know of it. Anyone out there seen something that does this? The closest I’ve seen is the “Footprints” experiment from 1999 by Alan Wexelblat and Pattie Maes … and even it wasn’t quite what Vannevar Bush was envisioning. (As I recall, Ted Nelson’s Xanadu project was quite interested in this sort of “trail” recording too … another reason why it’s sad it never took off.)
At any rate, the reason this subject is on my mind today is that I saw the New York Times story about the two Youtube founders preparing to revamp and relaunch Delicious. Though Delicious had long been left to moulder by Yahoo, and its basic genius — letting you publicly bookmark things you’ve found online — has been superseded by newer services like Diigo, I’ve often felt Delicious comes closest to evoking the trail of people’s mental associations as they find things online. Indeed, one of my favorite things is to save a bookmark on Delicious, and then check to see how many other people have bookmarked it. If several hundred have done so, that’s somewhat interesting; I know the site is popular. But if the site has been only bookmarked by only three or four other people — out of Delicious’ five-million-plus user base — then I know something much more interesting: That those two or three other people and I share some strange, oddball intellectual overlap. So I’ll inevitably bounce over and look at all of their bookmarks, and it feels like getting a very slight glimpse, in a Bushian sense, of the way they think. (For example, a few days ago I bookmarked this academic study of how online and offline teaching styles compare, and saw that only four other people had saved it. One of those users was “Sue Folley”, who, as you might suspect, had saved a ton of stuff about education … but also this fascinating post about why it’s hard to think of a question during the Q&A period after a lecture. I think I’ve probably generated a half-dozen Wired columns purely by perusing the mind-map someone else has autogenerated for me online.)
Anyway, when I read the New York Times piece I grew faintly hopeful that the Youtube guys will push Delicious in a vaguely “As We May Think” direction. As the story noted:
But the new Delicious aims to be more of a destination, a place where users can go to see the most recent links shared around topical events, like the Texas wildfires or the anniversary of the Sept. 11 attacks, as well as the gadget reviews and tech tips.
The home page would feature browseable “stacks,” or collections of related images, videos and links shared around topical events. The site would also make personalized recommendations for users, based on their sharing habits. “We want to simplify things visually, mainstream the product and make it easier for people to understand what they’re doing,” Mr. Hurley said.
Mr. Chen gives the example of trying to find information about how to repair a vintage car radio or plan an exotic vacation.
“You’re Googling around and have eight to 10 browser tabs of results, links to forums and message boards, all related to your search,” he said. The new Delicious, he said, provides “a very easy way to save those links in a collection that someone else can browse.”
If you added some sense of chronology-of-discovery to those “collections”, you’d have something approaching Bush’s “trails”.
UPDATE! Cory Doctorow posted about the entry on Boing Boing, and in the comments, people listed several web tools that approximate the Vannevar Bush idea of “trails”. Some of the ones listed:
- “Pathways”: this one produces a map of pages as you go through Wikipedia. It’s Mac only, and I’m not sure if it currently works.
- “How’d I get here?”: A plug-in for Firefox, which sadly now appears to be defunct, but which would show you the page on which you first clicked a link to the page you’re currently on.
- “Tab History Redux”: another Firefox plug-in — Open new tab, and it’ll save a record of which link it came from.
- “Voyage”: this is the closest one yet! A Firefox plug-in that displays pathways of your surfing as visual maps. Not sure it still works though.
- “Wikipedia contrails”: Matt Webb posted about his project in which he would list Wikipedia pages, manually, as he went through them — the Wikipedia “contrail”. Very fun! Not automated though.

Some sad news: Michael Hart, the founder of Project Gutenberg, passed away this week. If you read any ebooks at all, you can thank Hart: He basically invented them. In 1971 he typed the text of the US Declaration of Independence into a University of Illinois computer so that it could be passed on, freely and ad infinitum, to other readers. Then he decided that’s how all books should be made available: Digitally, instantly, and globally. He founded Project Gutenberg and began scanning or typing in public-domain works; as of this month the project has a capacious catalogue of 36,000 free books. (The New York Times published an obituary today, and there’s a nice commemoration here too.) This was crazy-awesome visionary stuff.
I use Project Gutenberg a lot, often in weirdly opportunistic ways. I’ll be walking down the street and suddenly remember an old book I read or looked at years ago, like Aristophanes’ The Clouds, or the gothic Canadian/British/Algonquin horror story The Wendigo. Then I’ll pull out my phone, launch the free ereader Stanza, download the book from Project Gutenberg, and start reading it — a process that takes 30 seconds. I’ve got about three dozen ebooks on the phone right now that I’m currently poking through. Every single time I use the service I think, man alive, this is how books should be: Instantly available for free. (Once they’re out of copyright, of course. Which ought to happen 14 years after publication, as Congress originally intended, instead of the current until-the-sun-explodes-or-we-run-out-of-lawyers madness … but I digress.) So basically I love Project Gutenberg to death.
Except for one thing: The books are almost totally unformatted.
Project Gutenberg’s are basically just plaintext. Hart understandably didn’t want to get swept up in the format/DRM wars between different vendors, precisely the sort that currently prevent you from moving a Nook book over to your Kindle or vice versa. It’s not that Project Gutenberg does no formatting; they hyperlink footnotes, make it easier to zip back and forth a bit. But other than that, the only formatting you get is whatever’s baked into your ereader software itself.
Which is capable and functional but … kinda bland. There’s no aesthetic joy in cracking open a Project Gutenberg title; it’s just you and the words. I can tolerate this, more or less, with novels and nonfiction. But the lack of formatting means Gutenberg’s poetry collections are often seriously deformed: The lines don’t break correctly, the spacings and indentations in modern poetry aren’t there; sometimes stanzas don’t even have the proper space between them. Ereaders like Stanza and Kindle enworsen (not a word, but should be) this situation, because they’re not designed to recognize and handle poetry. If a line is, say, too long to display in a single row of text, they wrap it around but don’t indent it, effectively destroying the line breaks the poet intended.
So while I’m a huge consumer of poetry, I’ve given up trying to read it using Project Gutenberg files. When it comes to poetry — particularly modern poetry — typography and layout aren’t just a fillip: They’re a core part of how the poem makes its meaning. That poem by e. e. cummings I put above? Imagine that turned into unformatted plain text, all the nuanced spacings turned into, I dunno, willy-nilly tab-separated chunks, and you get the picture. (BTW, I’ve found drama suffers from the same problem sometimes, too — particularly verse drama.)
I thought it was just me being a crank about this stuff. But as it turns out, I’m not alone. While reading some of Hart’s own essays this morning, I was intrigued to discover that people frequently complained to him — heatedly — about the absence of formatting. As he writes:
The thing I perhaps like least about eBooks is how many people in the world think it is my job to make eBooks come out exactly that way they think is the best in the world, and constantly harass me to change to this format or that one as the only, or primary, one of all the formats in the world.
Sorry, CONTENT is what Project Gutenberg provides but not FORMAT, FORM, FORMALITY, etc.
Let’s face it, but when even the plainest of plain text eBooks is created, 99% of the work of re-creating it into another format is already done, all YOU have to do is change 1% and you can have it any other way you want it. On top of this, there are many format conversion programs out there that will do most of this for you.
It’s funny how something that has already done 99% of the labor’s time and effort can be so vilified for not doing the other 1%.
Two things are interesting here. First, he’s quite right that I could change the 1% of the text to make a Gutenberg file more beautiful. And second, I’m probably not going to do it. I’ll either tolerate it or pay some money to somebody who can make it prettier for me.
And that, it occurs to me, presents some interesting possibilities for the ecosystem — and economics — of ereader software.
There’s a mountain of public-domain works out there, and while they can all be gotten for free via Stanza and Kindle and Nook, they all look like crap. They’re missing illustrations, frontispieces … anything to make their reading lush and lovely. True, Google’s mobile ereader offers old-school books in their original typography, but the viscissitudes of scanning and age mean they’re often less than legible, particularly on weensy screens.
Why doesn’t someone hoover up old, out-of-print books from Project Gutenberg and create ereaders that deliver the text using lovely, to-die-for aesthetics? Or to-die-for intellectual add-ons — as with Bob Stein’s prediction that we’ll one day have a class of marginalia-writers so good you’ll pay to have their notes and commentary appear in your digital copy of a book. Seriously, I’d pay for that.
Now, one could point out that this problem of aesthetics isn’t limited to Project Gutenberg books. At the moment, the great mass of commercial ebooks — i.e. the contemporary books you buy via the Kindle, Nook, Sony and Apple ebooks — are all super bland. But there’s nothing a third-party designer can do about that problem, because most of what’s being read on Kindles, Nooks etc is modern, copyrighted stuff. You can’t legally suck the text out and plunk in into a designed environment that makes it look more lovely. The out-of-copyright works in Project Gutenberg, in contrast, are a rich field that smart designers could plough, and likely a profitable field too. Indeed, print publishers have long made plenty of dough off of out-of-print works: They’re constantly bringing out new editions of classic old novels, and enticing buyers with gorgeous paper or cover design or an intro written by somebody famous.
Indeed, I can already spy experiments like this emerging in the ereader world. In a hunt to find any sort of vaguely-aesthetically-pleasing poetry viewer for the Iphone, I happened upon Poem Flow. It’s a very cool app: It displays poems line by line, fading in and out of view. You can control the rate at which the lines flow (I prefer ‘em pretty fast), and if you want, view the whole poem as one static page. And it’s a freemium model: While it comes with 20 poems installed, if you want more it’s 99 cents for three months of daily updates, or $2.99 for a year. I paid up.
People may not pay for out-of-print text, but they’ll pay for awesome aesthetics.
(By the way, I don’t intend this discussion as a criticism of Hart’s remarkable work. I don’t think Project Gutenberg should be formatting texts; it’s something best left to other folks, and indeed in that interview Hart talks about how Project Gutenberg actively works with people who want to do that 1% of the formatting to transform a free work. What interests me here is how Project Gutenberg’s work has opened up a potentially cool new area of ebook design … should any designers pick up the challenge.)
I’m a twitchy guy.
I have a huge amount of nervous energy, which I expunge via nearly-constant motion: I bounce my leg up and down, drum all sorts of polyrhythms on tables and desks, and — when my hair is longer — twiddle it. When I get all three going at once, which occurs with a certain dread periodicity (usually when I’m on deadline), I probably seem like some sort of tweaking meth-head. When I’m in public I tend to keep an eye on this behavior so that I don’t look too weird. I’ll bob my leg up and down — but very, very gently.
Occasionally, though, I’ll be sitting in a cafe, reading the paper, enjoying my ninth or tenth coffee of the morning and gently vibrating … when someone a table over will look over at me with a frown and say: “Do you have to do that?” Mortified, I’ll immediately cease all motion.
This doesn’t happen often. But it happens regularly enough that I’d long begun to suspect there is some fraction of the public who — for some reason — are sensually predisposed to hate the sounds and sights of twitchy people.
It turns out my suspicions were correct! In today’s New York Times science section there’s a great story about “misophonia”:
For people with a condition that some scientists call misophonia, mealtime can be torture. The sounds of other people eating — chewing, chomping, slurping, gurgling — can send them into an instantaneous, blood-boiling rage.Or as Adah Siganoff put it, “rage, panic, fear, terror and anger, all mixed together.”
“The reaction is irrational,” said Ms. Siganoff, 52, of Alpine, Calif. “It is typical fight or flight” — so pronounced that she no longer eats with her husband.
The article focuses on the sounds of people eating, but online resources note that many of the things I do — leg tapping, hair twirling — are also frequent triggers for misophonic rage.
And fascinatingly, it is rage: The folks with misophonia quoted in the Times talk about how they feel their blood boiling when they’re bombarded with a trigger, until they’re compelled to speak out. (“If I don’t say anything, the rage builds,” one notes. And interestingly, for her, the act of speaking out quells her misophonia, at least temporarily.) It also realized that though I don’t think I have misophonia, there are times when I’m so repelled by the noise somebody makes while eating that I, too, want to yell at them.
Nobody’s sure what causes it; some neuroscientists believe it’s hard-wired. And certainly nobody wants it: It makes their lives miserable, sometimes ruining friendships when they can’t tolerate they way someone eats or pronounces the letter “p”.
At any rate, it’s going to make me ever more careful to control my twitchiness in public places, particularly where other people are trying to work or read.
(That photo of tapping fingers courtesy the Creative-Commons-licensed Flickr stream of George Hatcher!)

On Sunday, Matt Richtel publishing a terrific piece in the New York Times lamenting how schools are blowing billions on high-tech gewgaws, despite little evidence showing it helps learning. Richtel unearths lots of grisly facts: Study after study has found that many popular tech initiatives — such as one-to-one laptops, interactive whiteboards, and “clickers” — don’t necessarily correlate with higher test scores, and sometimes they correlate with lower ones. This hasn’t stopped schools from blowing tons of dough: The Arizona district of Kyrene has spent $33 million in tech since 2005, yet scores have “stagnated” even as those across the state have, overall, risen. Amazingly, Kyrene is nonetheless asking voters to approve another $46.3 million for school technology over the next five years. As one teacher in the district complains, “we have Smart Boards in every classroom but not enough money to buy copy paper, pencils and hand sanitizer.” Nice.
Richtel neatly points out the various forces that drive this trend. Some of it is fuzzy thinking in educational policy circles, like “engagement” — the idea that classroom tech gets kids inherently more excited about being in class, so it’s worth buying even if test scores don’t budge. Even more insidious is the private-sector problem. These school tools are made by for-profit firms who often seriously overinflate the value of their warez, and when they go out of business (as many do), schools wind up with tech that slowly breaks down and can’t be fixed. Richtel doesn’t address this latter point directly in his piece, but I’ve had teachers regale me with sad tales of $4,000 whiteboards that are left to gather dust after they go poof and the vendor has shuttered. The education-tech sector is a lucrative market, of course; about $10 billion a year in public money is spent on in-classroom tech alone, which brings out not just innovators but snake-oil merchants.
As you read the piece, you could be forgiven for thinking: Man, let’s just unplug the whole school system! Why not just take every penny spent on tech and spend it instead on real live teachers? They’re a “technology” the value of which we’re much more confident. What’s the matter with sticking solely with pencils, paper, chalkboards and books? It worked for centuries.
Except halfway through the piece, Randy Yerrick — an associate dean of educational tech at the University of Buffalo — makes the take-away point: The chief reason to use high-tech tools is when you want to teach in a fashion that has “no good digital equivalent”. Or to put it another way, only use computers in situations where you want to do something that can’t be done without them.
So the question becomes: What exactly are these things? What types of teaching do computers make uniquely possible?
As it turns out, I’ve been asking lots of innovative teachers precisely this question over the last year as I’ve researched my book. They’ve tended to agree on the same list of concepts, some of which are really interesting and not the obvious ones. (Google! Video!) For example:
1) Teaching complexity. Computers are great at teaching concepts that are hard to grasp when you merely read about them, or try to execute them with pencil and paper. Lots of math and logic falls into this category. Peer at the textbook all you want, but it’s hard to get a deep, mentally sensual grasp of what’s going on until you experience the concepts unspooling before your eyes.
For example, consider the behavior of complex systems, and the “butterfly effect”: How tiny changes over here can produce a massive change over there. Years ago, Seymor Papert pioneered the Logo programming language precisely to allow for this sort of discovery. (It in turn inspired today’s Lego Mindstorm programming language.) You can sit a kid down, and have her create a simple program for a robot — like “go forward two feet, turn 20 degrees to the right, go forward one foot, then turn 30 degrees to the left”. Turn the robot loose and, whoo-hoo, emergent complexity! Then you change one tiny part of the robot’s behavior — say, make the second command 10 degrees instead of 20. Turn it loose again and behold the dramatically different results. (Or you can be like even more ambitious, like these folks, and have a bunch of middle and high school girls design Lego search-and-rescue robots, which requires them to engage in incredibly methodical thinking about how to break down a task into components.) Video games, too, can be superb at teaching these “butterfly” lessons. I’m often hesitant to recommend video games as classroom tools — in part because they’re so rarely used correctly in classes — but almost every game is a complex system that encourages experimentation: Change one tiny piece of your strategy in Civilization (or, hell, your strategy in Tetris) and watch everything fall apart.
The point is, the bewildering complexity of systems is an incredibly important thing to learn if you want to navigate life. Ask any CEO who nearly destroys her firm by making a seemingly insignificant change in strategy, or any farmer tinkering with his crops. Yet complexity is also an extraordinarily difficult thing to teach using traditional books and paper — because the linear, written text isn’t the best place to apprehend the results of many different, subtle, if-then experiments. Computers, in contrast, are fabulous at doing this; it’s part of what they were invented for. This is why students should mandatorily be taught at least a bit of computer programming. Plus, coding inevitably leads you to making stuff that you can show to other people, which, as Papert points out in this paper (PDF warning), is a massive motivator for kids:
We all learn better when learning is part of doing something we find really interesting. We learn best of all when we use what we learn to make something we really want. The second big idea is technology as building material. If you can use technology to make things you can make a lot more interesting things.
2) Seeing patterns in the world around you. Computers are also great at doing data visualization — helping students quickly see patterns in massive corpuses of data. This doesn’t have to mean big, scary number sets, by the way: Tools like Wordle let you do see patterns in text, like a poem or blog post. (That word cloud above is this very post rendered as a Wordle.)
In fact, one of my favorite data-viz examples is how this Spanish teacher had her students improve their writing skills by having them generate Wordles of their essays. The students could “see” their overuse of various rote phrases, because those words loomed huge in the Wordle. This, in turn, goaded them to use a more varied vocabulary: They’d plug each revision into Wordle and see how the number of overly large words shrunk. By the third draft, the class’ vocabulary usage had grown by a remarkable 30%.
Obviously, you can do this sort of word-counting and plotting with pen and paper; painstaking counting of word-occurrence in newspapers is how George Zipf discovered the Zipf curve. But it’s so much more sluggish to accomplish this without computers that the impact of the lesson evaporates.
3) Dialogue. Computers also let teachers and students have dialogues that aren’t easily possible in regular face-to-face formats. Learning how to get up and speak in class is a crucial skill, of course. But lots of teachers have told me that running an online class discussion — via an internal blog, or even a hash-tag mediated twitter stream — encourages far more students to speak out more often. Previously shy ones feel more free to contribute; others who normally “hate” writing sometimes begin pouring out a torrent of prose. Why? Because online dialogue is writing that has an “authentic audience,”, to use the lovely phrase of a group of New Zealand teachers who’ve pioneered the use of blogs in some very poor school districts.
This is a short and super-incomplete list, of course. But this is the way school boards ought to be thinking. They shouldn’t be blowing money trying to use tech to replace perfectly excellent old-school teaching techniques. They should be using computers to invent new ones.
And this doesn’t have to require much money. Arizona’s drunken-sailor spending to the contrary, the coolest classroom experiments I’ve seen used technology that was free or near-free, via open-source software and hardware and free web apps. Google Docs is a big one: There are obviously privacy issues with it, but virtually every teacher I’ve spoken to says it’s insanely useful without costing a dime. The same goes for free blogging, video and status-updating tools.
Even the hardware doesn’t need to cost so much. Hell, if I were running a school — and here is where I leap off the edge of my own personal flat earth — I’d buy only good-quality but inexpensive netbooks, then wipe the hard drives and instal Ubuntu’s Linux. (Or to really have fun, maybe I’d buy a bunch of these unbelievably cheap $25 Raspberry open-source computers; add a $100 monitor and $25 keyboard-mouse combo, and you’d have a desktop so inexpensive it almost wouldn’t matter if it broke.) And oh, yeah, clickers and whiteboards? Pffft. I’d round up an afterschool class of students interested in Maker culture and roll my own using Arduinos and Radio Shack parts, then open-source the design and watch as the world hacker community becomes a source for superb tech support and development. (There are already hackers making Wiimote-driven whiteboards, for example.)
The thing is, most of this classroom tech isn’t rocket science. And it’s fun to make! Schools that built their own tech with student participation would not only produce a crop of awesomely educated kids, but the school would control its own technological destiny, instead of being at the mercy of for-profit companies.
Granted, I’m undoubtedly glossing over innumerable red-tape barriers. School tech purchases have to satisfy byzantine state and local regulations of which I’m only dimly aware, and there are regulations in place requiring schools to rigorously filter the Internet; I’m not sure how if net-nanny software exists for Linux. But the point remains: The open-source pathway is a powerful and inexpensive one that schools ought to take as often as possible. There’s no reason to blow precious tax money on high tech that doesn’t teach.
Yesterday I was poking around on Instagram, and one of the people I follow put up a picture of the Canadian National Exhibition.
If you’ve never been to it, the CNE is pop-up amusement park that is enormously fun but, unusually by Canadian standards, extraordinarily seedy. Much like a backwater US county fair, it’s got rides operated by creepy-looking dudes who appear to be on weekend leave from a minimum-security prison; inedible funnel cakery; and “skill” games where the top prize is a refrigerator-sized Pikachu, the label of which frantically assures you that the stuffing is “new”. At any rate, this is how I remember it from my youth in the late 70s and early 80s. It may have cleaned up its act since, but I sort of hope not; I enjoyed the sense of Caligulan decay.
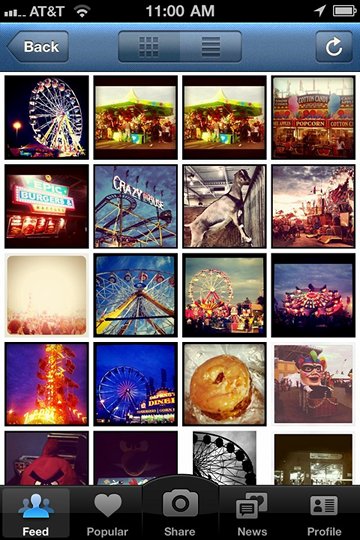
When I saw the CNE Instagram picture, I noticed the Instagrammer had tagged it — with #cne — and that clicked through to a constellation of 517 pictures, all taken in the last day or so. (That’s them, above.) This was Proustian stuff; it brought me right back to childhood! The Crazy Mouse ride, teetering on its improbably tiny rails! The ferris wheel aglow at night! The goats! (At the CNE there’s a building devoted, with steadily mounting anachronism, to local Canadian farming.)
And those tagged pictures made me think of a book I’d just finished reading earlier that same day: The Augmented Mind by Derrick de Kerckhove. De Kerckhove was a colleague of Marshall McLuhan back in the day, and he still carries his intellectual torch. Now, if you’ve read any Marshall McLuhan or Harold Innis — McLuhan’s lesser-known but kind-of-cooler Canadian economist intellectual midwife — you’ve no doubt mused on how different communication tools influence us. Innis called it the “bias” inherent in each form of communication. McLuhan rebranded that concept as “the medium is the message”, the much-catchier phrasing, but they both push the same idea: That how a medium functions is far more interesting and powerful than the content that travels over it. So for McLuhan, the real impact of electricity was the emergence of simultaneity, the real impact of print was linearity, etc. (Newspapers didn’t much impress him: “Today’s press agent regards the newspaper as a ventriloquist does his dummy.” That was 1964!)
Today you could ask: What’s the “bias” of the Internet? Plenty of ink has been spilled on this subject, but almost nobody uses Innis’ obscure terminology. So I was thus intrigued earlier this week when I stumbled upon an interview in which de Kerchkove used precisely that phrasing. He was talking about why he wrote The Augmented Mind, and said …
“Still in line with the Toronto School of Communications approach, I was trying to identify the bias of the medium of the Internet.
The Internet’s core principle of operation is packet switching. I found that for packet switching to carry the information in the right order to the right place, the precision of the whole system was owed to a unique way of dividing the information into short strings (or packets) and addressing each one with its unique label and position in the sequence to reconstruct the message wherever needed. That, in essence is the tag. Without the possibility to isolate, identify, and connect each packet there would neither Internet nor World Wide Web. Tagging hence by making any information available on demand is the core, the soul of the Internet. Tags allow to connect analog to digital media, and to interconnect everything with everything else end-to-end on demand. We are today in the midst of what I have called the era of the tag.”
A provocative idea! Alas, de Kerckhove doesn’t actually unpack this very much in the book itself, other than to offer up that neatly McLuhanesque koan: “A tag is the soul of the Internet.” But I dig the fractal quality of it. Tags are how everything online — from packets on up to entire documents — are recombined and made new sense of.
What’s particularly cool, for me, is that this makes re-interesting a tool that had become pretty blasé: The tag. Sure, tagging was intellectually hot six or seven years ago when people first began affixing them en masse to blog posts, bookmark links, Flickr pictures, and eventually tweets. And for a while there was the conversation about “folksonomy”, the way that mass tagging was more disorganized than formal library taxonomies (I call that photo “my_adorable_cat”; you call it “cloying”) but it allowed for very rapid organization and sorting of online stuff. But this is where tags quickly began to seem rather humdrum to me — just a piece of plumbing in everyday online life. You visit a tumblr site, use the tags to quickly sort through a bunch of posts. Big whoop.
But yesterday I started clicking around on those Instagram tags. (For the first time, actually: I am probably the last Instagram user on the planet to realize they were there.) And all of sudden I found them surprisingly affecting and powerful. Why? Probably because Instagram’s content is visual. The tags create a sort of “Thirteen Ways of Looking at a Blackbird” effect: You see the same scene over and over again, but through many people’s different viewpoints. In the constellation of CNE images above, one person picks out the massive creepy clown head; another, the “Epic Burgers”; another, the goat. While poking around in the pictures, I noticed the CN Tower lurked in the background — Toronto’s famous landmark — and the photographer had tagged it. So I clicked that tag and boom, I got the same experience of multiply re-seeing the CN Tower:

I like these different views: It’s a tourist trap, a play of light, a bow-chicka-bow phallic piece of 1970s architecture, and even a barely-noticeable spec in the distance when you’re out in the Toronto countryside.
Here’s another thing: The perceptual effect is of all these tagged photos is really strengthened by Instagram’s filters. If you see a zillion pictures of the same statue on Flickr, you’re like, oh, cool, interesting. But here, the filters make each point of view seem somehow more different and more alien from the others. And here’s another fun time-waster I got sucked into: Surfing the tags for the filters themselves. Each filter has a name; “Earlybird” is the one that sort of blows up the light in the center of the picture, mutes the colors, and rounds the edges of the picture. So when someone tags their photo with “Earlybird” you click on it and wind up seeing the inverse of the 13-blackbirds effect: Instead of viewing a single scene through many differently-filtered views, you see lots of different things — a car, two people kissing, a garbage can, a plane flying overhead — all filtered the same way: The world viewed from the perspective of the filter Earlybird, as it were.
Okay, enough of these stoner epiphanies! The point is that Instagram’s tags, primed by de Kerckhove’s provocation, made me think anew about the cognitive power of tags — their sense-making ability. But I also realized I haven’t seen designers do anything particularly interesting with tags in a while. I haven’t seen anything that helps me spy patterns in data/documents/pictures in similarly weird and fresh ways. Maybe tagging, as a discipline, hasn’t been pushed in very interesting ways. Or maybe I haven’t been looking in the right place?
(Irony of ironies, I realize I’ve never bothered to tag my blog posts.)
I'm Clive Thompson, the author of Smarter Than You Think: How Technology is Changing Our Minds for the Better (Penguin Press). You can order the book now at Amazon, Barnes and Noble, Powells, Indiebound, or through your local bookstore! I'm also a contributing writer for the New York Times Magazine and a columnist for Wired magazine. Email is here or ping me via the antiquated form of AOL IM (pomeranian99).

ECHO
Erik Weissengruber
Vespaboy
Terri Senft
Tom Igoe
El Rey Del Art
Morgan Noel
Maura Johnston
Cori Eckert
Heather Gold
Andrew Hearst
Chris Allbritton
Bret Dawson
Michele Tepper
Sharyn November
Gail Jaitin
Barnaby Marshall
Frankly, I'd Rather Not
The Shifted Librarian
Ryan Bigge
Nick Denton
Howard Sherman's Nuggets
Serial Deviant
Ellen McDermott
Jeff Liu
Marc Kelsey
Chris Shieh
Iron Monkey
Diversions
Rob Toole
Donut Rock City
Ross Judson
Idle Words
J-Walk Blog
The Antic Muse
Tribblescape
Little Things
Jeff Heer
Abstract Dynamics
Snark Market
Plastic Bag
Sensory Impact
Incoming Signals
MemeFirst
MemoryCard
Majikthise
Ludonauts
Boing Boing
Slashdot
Atrios
Smart Mobs
Plastic
Ludology.org
The Feature
Gizmodo
game girl
Mindjack
Techdirt Wireless News
Corante Gaming blog
Corante Social Software blog
ECHO
SciTech Daily
Arts and Letters Daily
Textually.org
BlogPulse
Robots.net
Alan Reiter's Wireless Data Weblog
Brad DeLong
Viral Marketing Blog
Gameblogs
Slashdot Games
