« PREVIOUS ENTRY
Mathematicians: Huge nerds in the U.S., rock stars in China
NEXT ENTRY »
Nader-trading is legal!
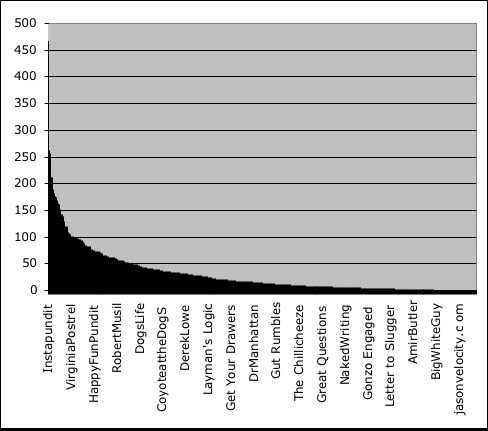
Check out the chart above: It illustrates the most popular blogs, ranked by their “inbound links” — the number of people who link to them. As is obvious, a very small number of blogs account for the vast majority of traffic.
There’s a great piece by Clay Shirky today about this phenomenon — it’s called the “power law distribution.” It basically notes that in a field of open competition, we normally expect that a plethora of choices will flatten everyone’s popularity. Think of it this way: Say I and a friend set up rival lemonade stands on our street. Say we were roughly the same quality, and had equally as good advertising and word-of-mouth. You would expect that we’d both get roughly half the street’s business, right? If another equally-similar rival showed up, they would pose competition — and the pie would be sliced three ways. Each new competitor flattens everyone’s popularity. Entire textbooks of traditional economics are based on this basic concept.
But that’s not the way the world works, does it? We all know this. We know that there are a couple of dozen almost-equally-good soft drinks out there, but somehow, Pepsi and Coke and Ginger Ale dominate. Same goes for TV shows, clothes, cars — you name it. This is because of the cardinal rule of “power law distributions”: One person’s choice affects another’s. Blogs have become the latest example of this, as Shirky notes:
If we assume that any blog chosen by one user is more likely, by even a fractional amount, to be chosen by another user, the system changes dramatically. Alice, the first user, chooses her blogs unaffected by anyone else, but Bob has a slightly higher chance of liking Alice’s blogs than the others. When Bob is done, any blog that both he and Alice like has a higher chance of being picked by Carmen, and so on, with a small number of blogs becoming increasingly likely to be chosen in the future because they were chosen in the past.
Think of this positive feedback as a preference premium. The system assumes that later users come into an environment shaped by earlier users; the thousand-and-first user will not be selecting blogs at random, but will rather be affected, even if unconsciously, by the preference premiums built up in the system previously.
Note that this model is absolutely mute as to why one blog might be preferred over another. Perhaps some writing is simply better than average (a preference for quality), perhaps people want the recommendations of others (a preference for marketing), perhaps there is value in reading the same blogs as your friends (a preference for “solidarity goods”, things best enjoyed by a group). It could be all three, or some other effect entirely, and it could be different for different readers and different writers. What matters is that any tendency towards agreement in diverse and free systems, however small and for whatever reason, can create power law distributions.
This is what’s interesting about power-law distributions: They aren’t about “merit”, at least in the way we normally think about it. It’s more like high school: Why is that guy popular? Because he’s popular. This is okay when it comes to blogs, of course. The stakes are lower; having a high or low-rated blog doesn’t — yet, anyway — matter too much to your livelihood. (Also, even a small audience can be useful. Though Collision Detection probably doesn’t have more than a few dozen people regularly linking to it, that’s enough to make it the #1 result for a Google search “Clive Thompson”.) Power-law distributions do no real harm online.
But in the real world of work, they’re much more troubling. As Robert Frank and Philip J. Cook noted in their superb, superb book The Winner-Take-All Society, power-law networks wind up massively rewarding people for minute, tiny, almost indistinguishable differences in talent. Increasingly, the guy making $40 million a year is only about 2% more qualified than the one making $400,000, and maybe only 5% more than the one making $40,000. Under power-law distributions, the workplace is now resembling the worlds of Olympic or pro sports — where being a tenth of a second faster than someone else, an amount that would normally be considered vanishingly negligible, separates those who remain amateurs from those who get gazillion-dollar endorsements.
Now for something completely different — well, almost completely different. If you’re interested in this power-law stuff, you might want to check out a feature I wrote last summer for the New York Times Magazine. It was about Richard Wallace, the creator of ALICE — one of the world’s most life-like chatbots.
ALICE “works” well because Wallace had a power-law epiphany: He realized that a tiny number of utterances — maybe 40,000 — make up over 95% of everything humans say in everyday conversation. To seem incredibly realistic, a chatbot didn’t need to have highly sophisticated artificial intelligence. All it needed was to have preprogrammed responses for those 40,000 everyday utterances:
Wallace had hit upon a theory that makes educated, intelligent people squirm: Maybe conversation simply isn’t that complicated. Maybe we just say the same few thousand things to one another, over and over and over again. If Wallace was right, then artificial intelligence didn’t need to be particularly intelligent in order to be convincingly lifelike. A.I. researchers had been focused on self-learning ”neural nets” and mapping out grammar in ”natural language” programs, but Wallace argued that the reason they had never mastered human conversation wasn’t because humans are too complex, but because they are so simple.
”The smarter people are, the more complex they think the human brain is,” he says. ”It’s like anthropocentrism, but on an intellectual level. ‘I have a great brain, therefore everybody else does — and a computer must, too.”’ Wallace says with a laugh. ”And unfortunately most people don’t.”
(Thanks to Boing Boing for originally pointing out Shirky’s piece!
Update: In the comment sections for this item, Jeff Liu has posted some extremely cool research related to power-law distributions; go check them out!
Also, I just noticed that the big-ass graphic at the top of this piece has once again stretched my blog template into a slightly wider-than-usual shape. I lack the requisite design kung-fu to fix it, so, there it is.)
I'm Clive Thompson, the author of Smarter Than You Think: How Technology is Changing Our Minds for the Better (Penguin Press). You can order the book now at Amazon, Barnes and Noble, Powells, Indiebound, or through your local bookstore! I'm also a contributing writer for the New York Times Magazine and a columnist for Wired magazine. Email is here or ping me via the antiquated form of AOL IM (pomeranian99).

ECHO
Erik Weissengruber
Vespaboy
Terri Senft
Tom Igoe
El Rey Del Art
Morgan Noel
Maura Johnston
Cori Eckert
Heather Gold
Andrew Hearst
Chris Allbritton
Bret Dawson
Michele Tepper
Sharyn November
Gail Jaitin
Barnaby Marshall
Frankly, I'd Rather Not
The Shifted Librarian
Ryan Bigge
Nick Denton
Howard Sherman's Nuggets
Serial Deviant
Ellen McDermott
Jeff Liu
Marc Kelsey
Chris Shieh
Iron Monkey
Diversions
Rob Toole
Donut Rock City
Ross Judson
Idle Words
J-Walk Blog
The Antic Muse
Tribblescape
Little Things
Jeff Heer
Abstract Dynamics
Snark Market
Plastic Bag
Sensory Impact
Incoming Signals
MemeFirst
MemoryCard
Majikthise
Ludonauts
Boing Boing
Slashdot
Atrios
Smart Mobs
Plastic
Ludology.org
The Feature
Gizmodo
game girl
Mindjack
Techdirt Wireless News
Corante Gaming blog
Corante Social Software blog
ECHO
SciTech Daily
Arts and Letters Daily
Textually.org
BlogPulse
Robots.net
Alan Reiter's Wireless Data Weblog
Brad DeLong
Viral Marketing Blog
Gameblogs
Slashdot Games
